
Wenn ich mich mit Kollegen aus dem Online-Marketing zum Thema Tracking und Attribution austausche, kommen wir sehr schnell auf Adblocker, DSGVO, Cookies und die damit einhergehenden gestiegenen Anforderungen. Geht man etwas tiefer in die Diskussion und betrachtet die Traffic-Kanäle, stellt sich heraus, dass bei vielen die Kanäle SEO und Direct am erfolgreichsten sind – sprich die Meisten Conversions darüber zustande kommen – während die Paid-Kanäle (z.B. SEA und Social) stagnieren oder gar zurückgehen. Den hohen Erfolg des Direct-Kanals erklärt der Großteil dann mit ihrer starken Brand.
Auch wir bei everysize können diese Aussage, basierend auf unseren Google Analytics Zahlen, bestätigen. Aber warum ist dem so? Aus Neugierde bin ich der Sache nachgegangen und habe mir die Ursachen für unseren hohen Conversion-Anteil im Direct-Kanal genauer angesehen. Dabei bin ich auf einige äußerst interessante Aspekte gestoßen, darunter: Je stärker wir unsere Paid-Kanäle skalieren, desto höher sind unsere Traffic- und vor allem unsere Conversion-Zahlen im Direct-Kanal!
Attribution != Traffic
Bevor ich einsteige möchte ich kurz definieren was ich unter Attribution verstehe. Bei der Attribution geht es darum Conversions (z.B. Verkäufe) einem Werbekanal zuzuordnen um somit den Erfolg des entsprechenden Kanals, vor allem im Vergleich zu den anderen Kanälen, beurteilen zu können (siehe auch Exatag: Marketing Attribution Part 1 ). Es geht also NICHT um den Traffic (Sitzungen, User etc.) eines Kanals, sondern um die Abschlüsse die daraus in Form von Leads und Sales resultieren und der entsprechenden Zuordnung. Die Definition ist wichtig, da die komplette Artikelreihe sich stets auf die Attribution bezieht.
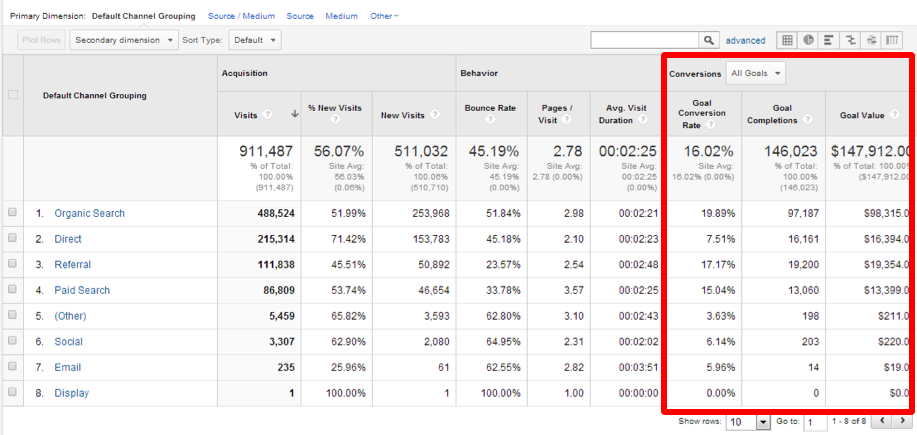
“Direct” – Das Sammelbecken an verlorenen Usern
Im Direct-Kanal landet alles was nicht eindeutig einem anderen Kanal zugeordnet werden kann. Es ist also ein Sammelbecken für alle möglichen Kanäle und lässt sich nur schwer wieder den eigentlichen Kanälen zuordnen. Man kann aber sagen – je “voller” das Becken, desto größer die Probleme und Herausforderungen.
Natürlich waren mir zahlreiche Ursachen für Direct-Traffic bekannt, z.B.
- Type-in traffic
- Bookmarks
- Links in E-Mails (e.g. Outlook)
- Mobile-Apps
- u.A., z.B.:
„Direct Traffic in Google Analytics entschlüsseln“ (DE)
„Dein Direct Traffic ist nicht, was er zu sein scheint“ (DE)
„In-Depth Guide on Direct Traffic in Google Analytics“ (EN)
„What is dark traffic in Google Analytics?“ (EN)
Eine Erklärung für den Zusammenhang mit dem Paid-Kanälen und warum Direct so viele Conversions hat, liefern diese aber nicht. In nahezu allen Quellen die ich finden konnte wurde stets empfohlen darauf zu achten möglichst überall UTM-Werte zu verwenden, um den Direct-Anteil gering zu halten. Da wir das aber bereits tun, konnte das nicht die Ursache sein.
Warum ein hoher “Direct”-Anteil für die Attribution so gefährlich ist
Die Gefahr, die von einem hohen Direct-Anteil ausgeht, lässt sich am besten anhand eines Beispiels darstellen:
Ein User klickt auf eine Facebook-Anzeige eines Shops. Er wird zum Shop weitergeleitet inkl. UTM-Parameter. Er kauft nicht direkt ein, sondern wartet einige Stunden. Erst danach legt er das Produkt in den Warenkorb und schließt den Kauf ab.
Tracking-Ablauf ohne Störfaktor
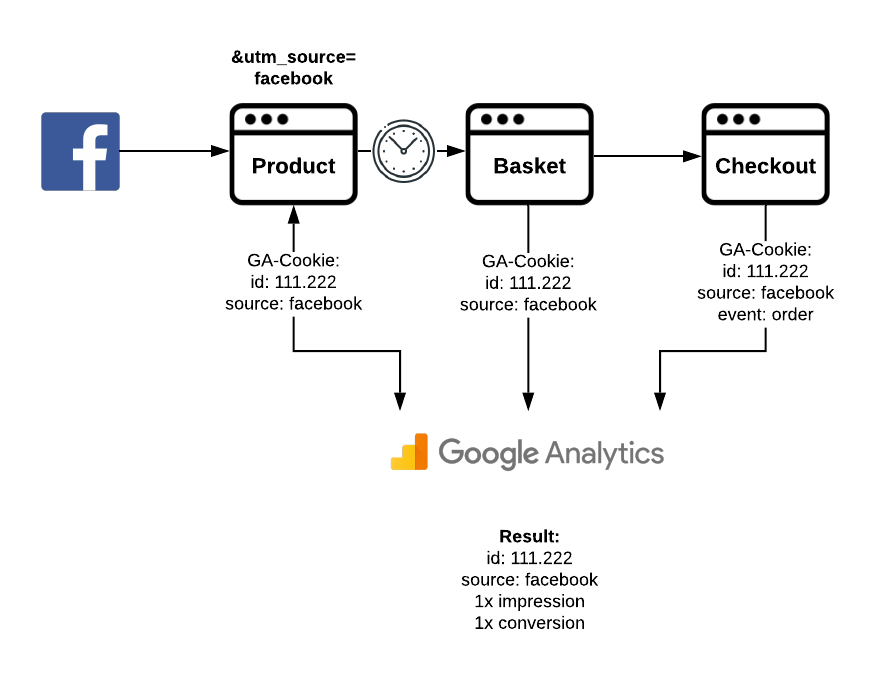
Google Analytics erfasst die Impression des Users und weist sie korrekt dem Facebook-Kanal zu. Der User erhält ein Cookie von GA mit der id 111.222. Einige Stunden später legt der Kunde das Produkt in den Warenkorb – GA identifiziert den Kunden anhand des Cookies und erfasst diesen korrekt. Der Kunde schließt den Bestellvorgang ab – der Händler sendet an GA ein Order-Event (z.B. via eCommerce-Tracking), das anhand des erkannten Cookies dem Kunden zugewiesen wird. Damit wird der Sale korrekt dem Kanal “Facebook” zugeordnet.
Tracking-Ablauf mit Störfaktor

Google Analytics erfasst die Impression des Users und weist sie korrekt dem Kanal Facebook zu. Der User erhält ein Cookie von GA mit der id 111.222. Es kommt allerdings zu einer Störung bei der das Cookie verloren geht (Ursachen hierfür s.u.). Einige Stunden später legt der Kunde das Produkt in den Warenkorb – GA kann den Kunden wegen des verloren gegangen Cookies nicht identifizieren, weshalb ein neues Cookie mit der id 333.444 erzeugt wird. Eine “Source” gibt es nun nicht mehr, da es sich um einen internen Link handelt – somit wird die Impression vermutlich dem Kanal “Direct” (oder evtl. “Other”) zugeordnet). Der Kunde schließt den Bestellvorgang ab – der Händler sendet an GA ein Order-Event (z.B. via eCommerce-Tracking), dass anhand des erkannten (neuen) Cookies dem Kunden zugewiesen wird. Ergebnis: Der Kanal Facebook wird geschwächt, da der Besuch zwar erfasst, aber keine Conversion zugewiesen wird.
D.h. “Direct” wird auf Kosten aller anderen Kanäle immer profitabler je häufiger eine Störung in der Customer-Journey auftritt.
Die (un)bekannten Störfaktoren
Im Zuge meiner tiefergehenden Recherchen bin ich dann auf verschiedene Ursachen gestoßen die Einfluss auf die Online-Attribution haben. In dieser Artikelreihe möchte ich auf einige weniger bekannte Attributions-Probleme eingehen und aufzeigen, warum viele Conversions fälschlicherweise in “Direct” landen:
- Privacy-Blocker – die unbekannte Gefahr (Teil 2)
- Frisst der “Privat-Modus” die Cookies? (Teil 3)
- Warum Paid-Kanäle auf Mobile schlechter konvertieren (Teil 4)
- Wie der Google Tag-Manager und Tracking-Weichen die Attribution verfälschen (Teil 5)
- Warum Cookie-Consent-Layer keine Lösung sind (Teil 6)
- Die Hoffnung stirbt zuletzt – mein Versuch eines Fazits (Teil 7)
Die Herausforderungen steigen
Um eines vorwegzunehmen – ich bin kein Schwarzmaler und ich möchte mit dieser Artikelreihe NICHT den Untergang der Online-Attribution einleiten. Ich möchte allerdings verdeutlichen, dass die Herausforderungen für ein ordentliches Tracking steigen. Es sind neue technische Lösungen notwendig und auch die Sichtweise auf die Beurteilung der Marketingkanäle muss überdacht werden. Die bisherige Vorgehensweise einfach überall Google Analytics bzw. den Google Tag-Manager einzubinden wird zukünftig nicht mehr genügen.